
はい、作者です。今日はテスターちゃんの話ではありませんw
表題の通り、自分が話した言葉をまぁリアルタイム…もといワンテンポ遅れでVOICEROIDに話してもらうプログラムを書いてみました。
動画を見ていただくのが早そうです。
githubにコードをおいています。
全ファイルのプログラム合計でたった69行!
これで作れるのは世の中の進歩のおかげ……。
今日はそのプログラムの説明をしたいと思います。
webを操作するためにseleniumと、Windowsアプリを操作するためにappiumを使っています。
これらはテスト自動化でよく使われるものです。
これも超最低限の構成で、webから要素を取得したり、ウィンドウズのアプリに文字列張り付けてボタンを押したりさせてます。
テスト自動化を勉強している人は、webの操作/windowsアプリの操作の最小限の構成がわかるかもしれません。
あとコードがわかれば応用も聞くので、音声認識を使ったアレコレも作れるかもしれません。
自分が話した言葉を音声認識させて保存させるような議事録取り的なものとか。
イベントでtwitterやzoomに来た最新チャットを読み上げるとか。
zoomにきた最新チャットをコメントスクリーンに回すとか。
様々考えられそうですね。
同じことがゆかりねっと様でも可能です。
プログラムなんてどうでもよくてツールだけ使いたい!という方はそちらがお勧めです。
やりたいこと
Vtuberをしたい。けど声がなぁ……。
よし。話した言葉をリアルタイムで音声認識させて、それをVOICEROIDで話してもらおう。
という思考です!
やりたいことをどんどん細かくしていく
まず音声認識ですが、様々あるけれどhtml上で使えるWebSpeechAPIがとっても手軽に使える上に精度が非常に高いです。
それを使うとすると、やりたいことを実現するためには以下のようなこと考えられます。

これを言葉で整理すると…。
- html(というかWebSpeechAPI)で、話した言葉を音声認識で文字列にする
- 何らかの手段でhtml上で認識した文字列を、windowsアプリのVOICEROIDの入力ボックスに張り付ける
- VOICEROIDの再生ボタンを押す
こういう形になりそうですね。
要はwebとwindowsアプリでデータを渡せばOK。じゃあこれをどう実現しようと考えるわけです。
そう考えていくと、自動テスト脳の人々は
「そうだ!Selenium(web自動化によく使われる)とAppium(アプリ自動化によく使われる)があるじゃん!」
となります。単に自分が使い慣れたものがパッと思い浮かぶわけですねw
その思考をベースに全体をどう組み立てていくか考えると……
- seleniumを使って、音声認識するためのhtmlを表示する
- htmlで音声認識をしたらwebに文字列を表示させる
- 表示された文字列をseleniumで取得する
- appiumで起動していたVOICEROIDの入力ボックスに文字列をappiumを使って張り付ける
- appiumを使って再生ボタンを押す
- 2~5をループさせる
他にもやり方は色々ありそうだけど、こんな感じで行けそうですね!
そんな考えで今のプログラムは作っています。
プログラムの説明
では、さっそくプログラムの説明をしていきます。
index.html説明
音声認識をして、認識した言葉を文字列として出力するhtmlです。
これ単品でも音声認識結果を確認できます。
長く見えますがコードとしては20行です。
(説明なしのコード)
<!DOCTYPE html> <html lang="ja"> <head> <script> //とりあえずchromeとfirefoxの両方の対応。chromeだとwebkitの接頭辞が必要。 SpeechRecognition = webkitSpeechRecognition || SpeechRecognition; //インスタンス化。音声認識を使いますよーという準備といったところ。 const recognition = new SpeechRecognition(); //以下をtrueにすることで、認識しっぱなしになる(ループしなくても何度も認識をちゃんとやってくれる) recognition.continuous = true; //音声認識が完了するたびに以下の{}が呼び出される。 recognition.onresult = (event) => { //これまで認識した全ての言葉をログに吐き出す。デバッグ用。 console.log(event.results); //最新の認識結果は配列の一番最後に入っている。 var index = event.results.length - 1; //最新の認識結果を変数textに入れる var text = event.results[index][0].transcript; //最新の認識結果をbodyの中にあるid=msgのdivタグ部分に表示させる。 document.getElementById("msg").innerHTML = text } //音声認識を始める recognition.start(); </script> </head> <body> <div id="msg">入力待ち</div> </body> </html>
これだけで音声認識をして、最新の認識結果をweb上に表示してくれます。
まず大事な点としては以下。
recognition.continuous = true;
これを設定しないと1回で認識が終了してしまいます。trueにしておきましょう。
沈黙が1分くらい続いた場合は自動的に終了します。
認識結果は以下のように入っています。
event.results[0][0].transcript; //1回目の認識結果
event.results[1][0].transcript; //2回目の認識結果
event.results[2][0].transcript; //3回目の認識結果
……
最新の認識結果はevent.resultsの配列の一番最後に入っていることになります。
ですので以下で最新が何番目かを取得しています。
var index = event.results.length - 1;
配列長 - 1 している理由は配列は[0]から始まるからですね。
(配列長が1だと[0]だけ、配列長が2だと[0]と[1])
document.getElementById("msg").innerHTML = text
これはhtmlの要素の中身を丸っと書き換える方法です。
意味は「msgというidのタグの中身をtextに書き換えてね!」という意味です。
model_selenium.py説明
これではseleniumでwebページを表示して要素を取ります。
ホント最低限。けどこれが基本の形です。
テスト自動化でseleniumをやってみる人の参考になるかもしれません。
説明を入れたから長く感じますが、コードだけだと10行ですw
(説明なしのコード)
#seleniumのwebdriverを使います、という文。インストールしているwebdriverのコードを呼び出す。 from selenium import webdriver #どこからでも呼び出しやすいようにModelSeleniumとう名前でclassを作る class ModelSelenium: driver = None #__init__はインスタンス化したとき(ModelSeleniumを使いますよーとやったとき)に最初に呼ばれるメソッド。 #引数のselfはclassのときは入れるヤツ。インスタンス化するときはurlだけ送ってあげる。 def __init__(self, url): #chromeのwebdriverを使いますよという文。 self.driver = webdriver.Chrome() #getを使うと、urlに画面遷移できます。 self.driver.get(url) #終了時に呼び出すメソッド。 def quit(self): #quitを使うと、webdriverが終了します。終わるときはちゃんとquitを呼び出しましょう(忘れがち) self.driver.quit() #タグに書かれているid部分に書かれているテキストを持ってくるメソッド def get_text_by_id(self, id): #find_element_by_idを使うと、そのidを持っている要素を指定することができます。 #さらにその後に続く.textで「idで見つけた場所から、記載されたテキストを持ってきてね」という意味になります。 return self.driver.find_element_by_id(id).text
classについては、説明をしているサイトがたくさんあるので説明は割愛します。
__init__メソッド説明
__init__はclassがインスタンス化された時に呼ばれるメソッドです。
以下でchromeを起動します。
self.driver = webdriver.Chrome()
そして以下で、引数で指定したurlに遷移します。
self.driver.get(url)
これが、seleniumでブラウザ起動してURLに遷移する最小構成です!
get_text_by_idメソッド説明
では次はget_text_by_idのメソッドです。
まとめて書いてしまってるのでちょっと分解して書いてみます。
まず以下で、htmlのタグでid=xxxと書かれている部分を指定することができます。
element = self.driver.find_element_by_id('xxx')
そのあと、以下でそのタグの中のテキストを取得できます。(hogehogeは適当な変数です)
hogehoge = element.text
それをまとめて書くと以下のようになるわけです。
hogehoge = self.driver.find_element_by_id('xxx').text
quitメソッド説明
操作が終わった後はちゃんと終了させてあげなければいけません。
それがquitです。
self.driver.quit()
結構忘れがち。
作ってるときにquitを忘れてブラウザを手動で閉じたりすると、プログラムは動いてるけどブラウザは消えちゃってて「プログラムどうしよう~」みたいな状態になります。(強制終了してね)
model_appium説明
これは、appiumでwindowsのアプリを起動して要素を操作します。
入力ボックスへの文字列張り付け、ボタンのクリックです。
ホント最低限。
テスト自動化でwindowsのアプリを自動化を勉強しようとしている人には参考になるかも。
説明を入れたから長く感じますが、コードだけだと16行ですw
(説明なしのコード)
#appiumのwebdriverを使います、という文。インストールしているwebdriverのコードを呼び出す。 from appium import webdriver #どこからでも呼び出しやすいようにModelAppiumとう名前でclassを作る class ModelAppium: driver = None #インスタンス化したときに最初に呼ばれる。引数はWinAppDriverのアドレス(http://127.0.0.1:4723)と、アプリのパス def __init__(self, addr, app_path): #apabilitiesに設定を渡すための入れ物を作る。辞書型。 desired_caps = {} #入れ物の["app"]にアプリのパスを設定してあげる desired_caps["app"] = app_path #アプリを起動する。 self.driver = webdriver.Remote( #引数で持ってきたWinAppDriverのアドレス。いじってない限りhttp://127.0.0.1:4723 command_executor=addr, #アプリのパスが入った辞書をcapabilitiesに設定してあげる desired_capabilities=desired_caps) #終了時に呼び出すメソッド def quit(self): self.driver.quit() #textを渡すと、それを入力ボックスに張り付けて、ボタンを押してくれるメソッド def play(self, text): #AutomationIdが「TextBox」である要素を指定する el = self.driver.find_element_by_accessibility_id("TextBox") #clearを使うと、入力ボックスに入っている文字を全部消せる el.clear() #send_keysを使うと、指定した要素に文字列を張り付けることができる el.send_keys(text) #find_element_by_nameを使うと、そのNameを持っている要素を指定することができる #.click()で指定した要素をクリックできます。けどその時マウスが持っていかれるので注意です。 self.driver.find_element_by_name("再生").click()
__init__メソッド説明
アレコレやっているように見えますが、アプリのパスを指定して起動してるだけです!
引数はWinAppDriverのアドレスと、アプリのパスです。
windowsのアプリはWindowsApplicationDriverというものを用いて動いています。
(細かな使い方はgithubの使い方を見てください)
そのアドレスを指定します。
まぁ、いじっていない限りはhttp://127.0.0.1:4723です。
アプリのパスは、普通にwindowsのそのアプリのアドレスバーに書いてあるパスです。
(c:\game\hogehuga.exe みたいな)
playメソッド説明
このメソッドでは、textを入力ボックスに張り付けて、再生ボタンを押す、という二つのことを行っています。
以下で、入力ボックスを指定しています。
el = self.driver.find_element_by_accessibility_id("TextBox")
ここではAutomationIdがTextBoxとなっている要素を指定します。
それってどうやって調べるの!?となりますが、それは最後の方に記載します。
(inspect.exe を使ったりします)
以下で、すでに入力されている文字列を削除しています。
el.clear()
自動テストでも繰り返す時ありがちですが、前回入力した内容が残ってるのですよね。
なので最初に消してあげてまっさらにしてから、新しい文字列を張り付けることになります。
以下で、textの文字列を入力ボックスに貼り付けます。
el.send_keys(text)
これで文字列を張り付けるまでは終了です。
その後はボタンを押します。
self.driver.find_element_by_name("再生").click()
find_element_by_nameでNameの要素が"再生"になっている要素を指定します。
(ここの確認方法も後述します)
そして.click()で指定した要素をクリックします。
seleniumの時と同じで要素の指定とクリックをまとめて書いた文です。
こちらではquitメソッドは割愛します。seleniumの時と同じです。
exec_realtime_voiceroid.py説明
今まで書いてきたseleniumとappiumを操作するメインプログラムです。
このプログラムで「やりたいことをどんどん細かくする」に記載した流れを実現します。
説明文を入れたので長く感じますが、22行のプログラムです。
(説明なしのコード)
#さっき作ったmodel_seleniumを読み込む import model_selenium #さっき作ったmodel_appiumを読み込む import model_appium #待ち時間を使うときに必要なtimeを読み込む import time #さっき作ったmodel_seleniumをインスタンス化(model_seleniumを使うよーってやる) #引数はindex.htmlのパス。ローカルのページを読み込むときはfile:///を使う。 selenium = model_selenium.ModelSelenium( "file:///D:/xampp/htdocs/音声リアルタイムボイスロイド変換/index.html" ) #さっき作ったmodel_appiumをインスタンス化 #WinAppDriverのアドレス(変えてなければこのままでOK)、アプリのパスを渡す。 appium = model_appium.ModelAppium( "http://127.0.0.1:4723", "C:\Program Files (x86)\AHS\VOICEROID2\VoiceroidEditor.exe" ) #「webから取得した文字列が前回から変わった」という判断をするための変数 old_text = "入力待ち" #無限ループ while True: #ただの無限ループだとbusyになる(フリーズする)ので0.1秒の待ちを入れる time.sleep(0.1) #model_seleniumのget_text_by_idメソッドを使って、msgに書かれているテキストを取得 text = selenium.get_text_by_id("msg") #取得したテキストが「終了」だった場合はループを抜けて終了する if text == "終了": break #前回の認識結果と新しい認識結果が違った場合 if text != old_text: #前回の認識結果を新しい認識結果を入れる old_text = text #デバッグ用。画面に認識した文字列を出す。 print(text) #model_appiumのplayメソッドを使って、認識したテキストを張り付け・再生する appium.play(text) #ループから抜けた後はseleniumとappiumをちゃんと終了させる。 selenium.quit() appium.quit()
準備部分の説明
以下のimportで、今まで作ったものを呼び出しています。
import model_selenium
import model_appium
これで先ほど作ったclassが使えます。
以下で、作ったmodel_seleniumとmodel_appiumをインスタンス化(これ使います!ってやるやつ)ができます。
selenium = model_selenium.ModelSelenium("file:///D:/xampp/htdocs/音声リアルタイムボイスロイド変換/index.html")
appium = model_appium.ModelAppium("http://127.0.0.1:4723", "C:\Program Files (x86)\AHS\VOICEROID2\VoiceroidEditor.exe")
ここで渡している引数は、それぞれの__init__メソッドに渡されます。
seleniumでは、先ほど作ったindex.htmlを開いています。
これはindex.htmlファイルを置いたパソコン上のパスを指定してください。
file:///D:/xampp/htdocs/音声リアルタイムボイスロイド変換/index.html
seleniumでローカルのファイルを指定したいときは
file:///
を使用します。
appiumでは、WinAppDriverのアドレスとアプリのパスを指定します。
先ほど描いたようにWinAppDriverのアドレスは変更してないなら以下固定です。
アプリのパスは特に説明しなくても良いですよね。
C:\Program Files (x86)\AHS\VOICEROID2\VoiceroidEditor.exe
パソコンでそのアプリが入っている場所を指定してください。
ループの説明
ここはどういう思考で作っているかというと
- seleniumを使って認識した文字列が表示される部分のテキストを取得する
- 今取得した文字列が前に取得した文字列と一致しなかったら、新しい音声認識があったと判断
- 新しい認識があった場合はappiumでvoiceroidに張り付け、再生を行う
こんな流れです。
old_text = "入力待ち"
ループ前にこれがあるのは、初期設定です。
もしこれを入れない場合、一番の初回はold_text(空っぽ)とseleniumで取得した文字列("入力待ち")が比較されます。
この比較をするともちろん違うので、新しい音声認識があったとされてしまい、appiumに「入力待ち」という言葉が送られしゃべってしまいます。
以下は無限ループの書き方。
while True:
正直、滅多に使いません。アブナイのですw
とはいえ今回はずーっと使うことを考えていますので、この形になります。
これを入れた場合は必ず、どういう条件で終わらせるかを入れる必要があります。
if text == "終了":
break
これですね。
「終了」と音声認識されるとこのプログラムは終了します。
これがないと本当に無限ループします。
あと、今回のような「待機のための無限ループ」には待ち時間も入れます。
time.sleep(0.1)
これがないとbusy wait(フリーズするような状態)になってしまうはず。
(怖くて試してないw)
0.1は待ち時間です。単位は秒。
待ち時間で単位が秒なコマンドは珍しいです。(他言語だと大体ミリ秒です)
さて、全体を通すとこんな感じです。
exec_realtime_voceroid.pyを実行すると、以下のことが一通り実行されます。
- seleniumを使って、音声認識するためのhtmlを表示する
- htmlで音声認識をしたらwebに文字列を表示させる
- 表示された文字列をseleniumで取得する
- appiumで起動していたVOICEROIDの入力ボックスに文字列をappiumを使って張り付ける
- appiumを使って再生ボタンを押す
- 2~5をループさせる
おまけ:Windowsアプリの要素の取得の仕方
windowsアプリを自動操作するためには、操作したい要素を何とかして取得しなければいけません。
そのやり方を二つお伝えします。
- inspect.exeを使用する方法
- WinAppDriver UI Recoderを使用する方法
inspect.exeを使用する方法
inspect.exeはwindowsに最初から入っているアプリです。
タスクバーから検索するとすぐ見つかります。
使い方は非常に簡単です。
検査したいアプリを起動。
そしてinspect.exeを起動して検査したいアプリの気になる部分にマウスを合わせれば情報が出てきます。
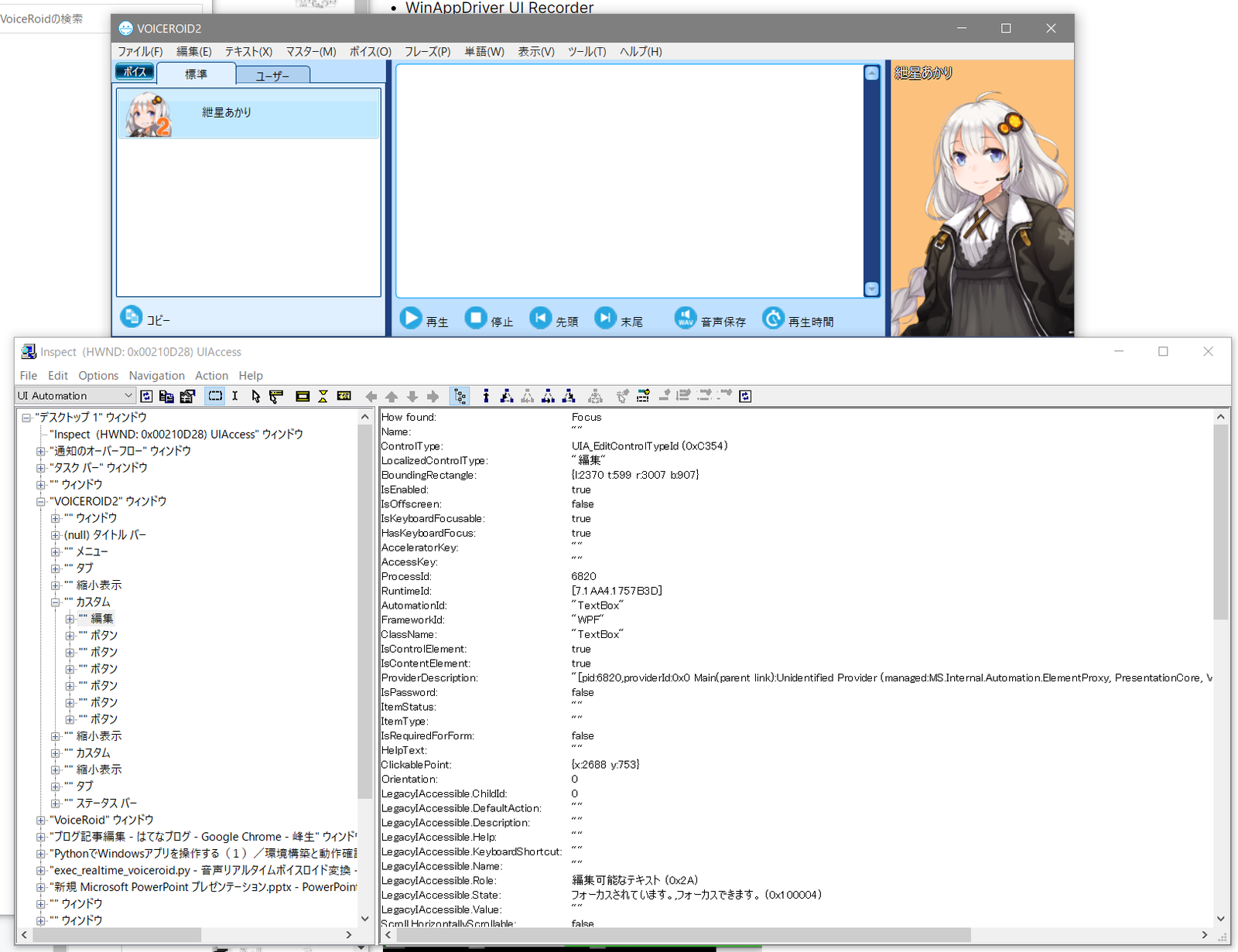
これは入力ボックス(編集)にカーソルを合わせたときの情報です。
今回はこれの「AutomationId」に記載された「TextBox」を要素を特定する部分として使用しました。
pythonで要素を指定する場合は以下のような対応でしょうか
- AutomationId -> find_element_by_accessibility_id
- ClassName -> find_element_by_class_name
- Name -> find_element_by_name
- LocalizedControlType -> find_element_by_tag_name
この辺に記載があります。
WinAppDriver UI Recorderを使う方法
こちらは以下からダウンロードして使用します。
WinAppDriverと一緒にあるので、ダウンロードするファイルを間違えないようにしてください、
こちらはというと、windowsアプリの操作を記録してくれます。
あと、困った時の心強い…いや弱いかも…な味方xpathを出してくれますw
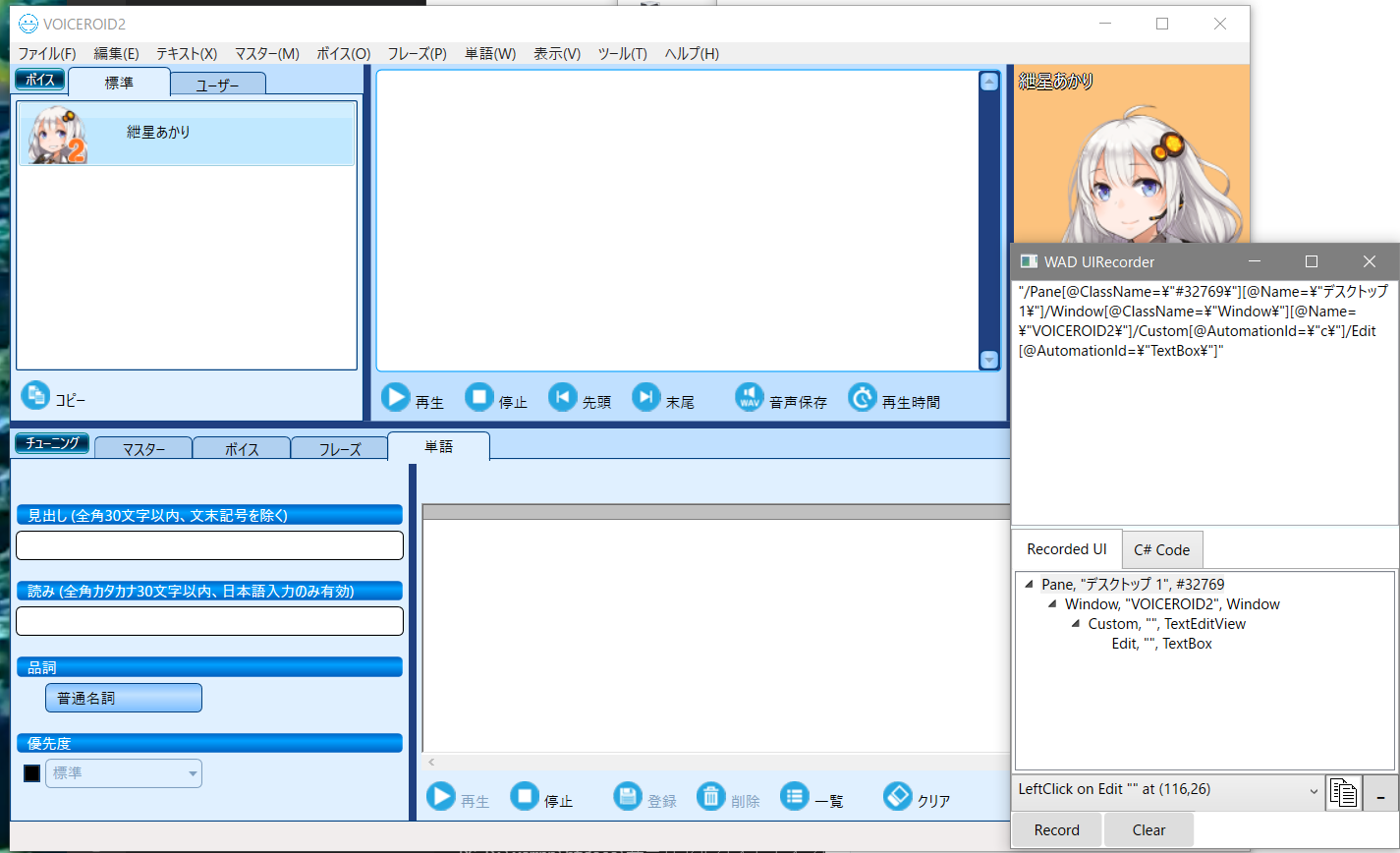
入力ボックスをクリックしたときのxpathは以下でした。
"/Pane[@ClassName=\"#32769\"][@Name=\"デスクトップ 1\"]/Window[@ClassName=\"Window\"][@Name=\"VOICEROID2\"]/Custom[@AutomationId=\"c\"]/Edit[@AutomationId=\"TextBox\"]"
再生ボタンをクリックしたときのxpath
"/Pane[@ClassName=\"#32769\"][@Name=\"デスクトップ 1\"]/Window[@ClassName=\"Window\"][@Name=\"VOICEROID2\"]/Custom[@AutomationId=\"c\"]/Button[@ClassName=\"Button\"]/Text[@ClassName=\"TextBlock\"][@Name=\"再生\"]"
voiceroidはfullpathを使わなくても最後の部分を見れば良さそうですね。